В этой главе рассматриваются представление списков и атомов в памяти машины, а также специальные функции, с помощью которых можно изменять внутреннюю структуру списков. Без знания внутренней структуры списков и принципов её использования изучение работы со списками и функциями остаётся неполным.
В чистом функциональном программировании специальные функции, изменяющие структуры, не используются. В функциональном программировании лишь создаются новые структуры путём анализа, расчленения и копирования ранее созданных структур. При этом созданные структуры никогда не изменяются и не уничтожаются структуры, значения которых уже не нужны. В практическом программировании псевдофункции, изменяющие структуры, иногда всё-таки нужны, хотя их использования в основном пытаются избежать.
Оперативная память машины, на которой работает Лисп-система, логически разбивается на маленькие области, которые называются списочными ячейками (cons). Списочная ячейка состоит из двух частей, полей first и rest. Каждое из полей содержит указатель. Указатель может ссылаться на другую списочную ячейку или на некоторый другой Lisp объект, как, например, атом. Указатели между ячейками образуют как бы цепочку, по которой можно из предыдущей ячейки попасть в следующую и так, наконец, до атомарных объектов. Каждый известный системе атом записан в определённом месте памяти лишь один раз. (В действительности в данной реализации языка можно использовать много пространств имён, в которых атомы с одинаковыми именами хранятся в разных местах и имеют различную интерпретацию.)
Графически списочная ячейка представляется прямоугольником, разделённым на части (поля) first и rest. Указатель изображается в виде стрелки, начинающейся в одной из частей прямоугольника и заканчивающейся на изображении другой ячейки или атоме, на которые ссылается указатель.
Указателем списка является указатель на первую ячейку списка. На ячейку могут указывать не только поля first и rest других ячеек, но и используемый в качестве переменной символ, указатель из которого ссылается на объект, являющийся значением символа. Указатель на значение хранится вместе с символом в качестве его системного свойства. Кроме значения системными свойствами символа могут быть определение функции, представленное в виде лямбда-выражения, несколько знаков, задающая внешний вид переменной, выражение, определяющее пространство, в которое входит имя, и список свойств.
Побочным эффектом функции присваивания setq является замещение указателя в поле значения символа. Например, следующий вызов:
>(nil setq list '(a b c)) nil
создаёт в качестве побочного эффекта изображённую серую стрелку.
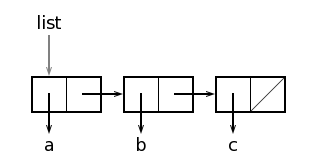
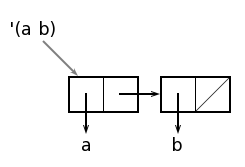
Список состоит из нескольких ячеек, связанных друг с другом через указатели в правой части ячеек. Правое поле последней ячейки списка в качестве признака конца списка ссылается на пустой список, т.е. на атом nil. Графически ссылку на пустой список часто изображают в виде перечёркнутого поля. Указатели из полей first ячеек списка ссылаются на структуры, являющиеся элементами списка, в данном случае на атомы a, b и c.
Работа селекторов first и rest в графическом представлении становится совершенно очевидной. Если мы применим функцию first к списку list, то результатом будет содержимое левого поля первой списочной ячейки, т.е. символ a:
>(list first) a
Соответственно вызов
>(list rest) (b c)
возвращает значение из правого поля первой списочной ячейки, т.е. список (b c).
Допустим, что у нас есть два списка:
>(nil setq head '(b c)) nil >(nil setq tail '(a b c)) nil
Вызов функции
>(nil cons head tail) ((b c) a b c)
строит новый список из ранее построенных списков head и tail так, как это показано на рисунке.
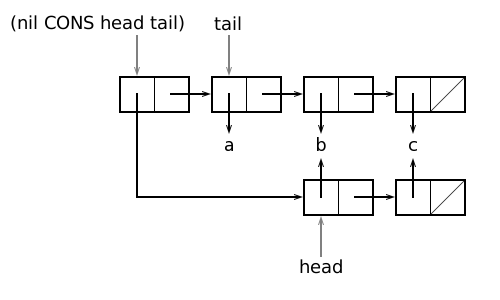
cons создаёт новую списочную ячейку (и соответствующий ей список). Содержимым левого поля новой ячейки станет значение первого аргумента вызова, а правого - значение второго аргумента. Обратите внимание, что одна новая списочная ячейка может связать две большие структуры в одну новую структуру. Это довольно эффективное решение с точки зрения создания структур и их представления в памяти. Заметим, что применение функции cons не изменило структуры списков, являющихся аргументами, и не изменило значений переменных head и tail.
На одну ячейку может указывать одна или более стрелок из списочных ячеек, однако из каждого поля ячейки может исходить лишь одна стрелка. Если на некоторую ячейку есть несколько указателей, то эта ячейка будет описывать общее подвыражение. Например, в списке
(кто-то приходит кто-то уходит)
символ кто-то является общим подвыражением, на которое ссылаются указатели из поля first из первой и из третьей ячейки списка.
Если элементами списка являются не атомы, а подсписки, то на месте атомов будут находится первые ячейки подсписков.
Из рисунка выше видно, что логически идентичные атомы содержатся в системе один раз, однако логически идентичные списки могут быть представлены различными списочными ячейками. Например, значения вызовов
>(nil setq list (nil cons head tail)) nil >(list first) (b c)
и
>((list rest) rest) (b c)
являются логически одинаковым списком (b c), хотя они и представлены различными списочными ячейками:
>((list first) = ((list rest) rest)) (b c)
Однако список (b c) может состоять и из тех же ячеек.
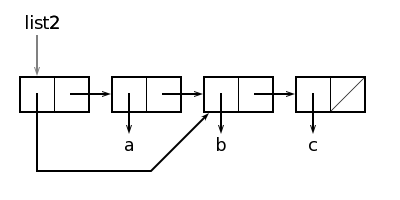
Эту структуру можно создать с помощью следующих вызовов:
>(nil setq bc '(b c)) nil >(nil setq abc (nil cons 'a bc)) nil >(nil setq list2 (nil cons bc abc)) nil
Таким образом, в зависимости от способа построения логическая и физическая структуры двух списков могут оказаться различными. Логическая структура всегда имеет форму двоичного дерева, в то время как физическая структура может быть ациклическим графом, или, другими словами, ветви могут снова сходиться, но никогда не могут образовывать замкнутые циклы, т.е. указывать назад. В дальнейшем мы увидим, что, используя псевдофункции, изменяющие структуры (поля) (setfirst, setrest и другие), можно создать и циклические структуры.
Логически сравнивая списки, мы использовали предикат =, сравнивающий не физические указатели, а совпадение структурного построения списков и совпадение атомов, формирующих список.
Предикатом eq можно определить физическое равенство двух выражений (т.е. ссылаются ли значения аргументов на один физический объект) не зависимо от того, является ли он атомом или списком. При сравнении символов всё равно, каким предикатом пользоваться, поскольку атомарные объекты хранятся всегда в одном и том же месте. При сравнении списком нужно поступать осторожнее.
Вызовы функции eq из следующего примера возвращают в качестве значения false, так как логически одинаковые аргументы в данном случае представлены в памяти физически различными ячейками:
>(nil eq '((b c) a b c) '((b c) a b c)) false >(nil eq list list2) false >(nil eq (list first) ((list rest) rest)) false
Поскольку части first и rest списка list2 представлены при помощи одних и тех же списочных ячеек, то получим следующий результат:
>(nil eq (list2 first) ((list2 rest) rest)) (b c)
Определяя базовую функцию cons, мы предполагали, что её вторым аргументом является список. Это ограничение не является необходимым, так как при помощи списочной ячейки можно было бы, например, результат вызова
(nil cons 'a 'b)
представить в виде структуры, изображённой на рисунке.
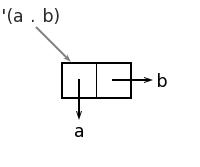
На рисунке показан не список, а более общее символьное выражение, так называемая точечная пара. Для сравнения на рисунке мы изобразили список (a b).
Название точечной пары происходит из использованной в её записи точечной нотации, в которой для разделения полей first и rest используется выделенная пробелами точка:
>(nil cons 'a 'b) (a . b)
Выражение слева от точки (атом, список или другая точечная пара) соответствует значению поля first списочной ячейки, а выражение справа от точки - значению поля rest. Базовые функции first и rest действуют совершенно симметрично:
>('(a . b) first) ; обратите внимание на пробелы, выделяющие точку
a
>('(a . (b . c)) rest)
(b . c)
Точечная нотация позволяет расширить класс объектов, изображаемых с помощью списков. Ситуацию можно было бы сравнить с началом использования дробей или комплексных чисел в арифметике.
Любой список можно записать в точечной нотации. Преобразование можно осуществить (на всех уровнях списка) следующим образом:
(a1 a2 … an)
≡
(a1 . (a2 . … (an . nil) … ))
Приведём пример:
(a b (c d) e)
≡
(a . (b . ((c . (d . nil)) . (e . nil))))
Признаком списка здесь служит nil в поле rest последнего элемента списка, символизирующий его окончание.
Транслятор может привести записанное в точечной нотации выражение частично или полностью к списочной нотации. Приведение возможно лишь тогда, когда поле rest точечной пары является списком или парой. В этом случае можно опустить точку и скобки вокруг выражения, являющегося значением поля rest:
| (a1 . (a2 a3)) | ≡ | (a1 a2 a3) | |
| (a1 . (a2 . a3)) | ≡ | (a1 a2 . a3) | |
| (a1 a2 . nil) | ≡ | (a1 a2 . ())≡ | (a1 a2) |
Точка останется в выражении лишь в случае, если в правой части пары находится атом, отличный от nil. Убедиться в том, что произведённые интерпретатором преобразования верны, можно, нарисовав структуры, соответствующие исходной записи и приведённому виду:
>'(a . (b . (c . (d)))) (a b c d) >'((a b) . (b c)) ((a b) b c) >'(a . nil) (a) >'(a . (b . c)) (a b . c) >'((((nil . a) . b) . c) . d) ((((nil . a) . b) . c) . d)
Использование точечных пар в программировании на Лиспе в общем-то излишне. С их помощью в принципе можно несколько сократить объём необходимой памяти. Например структура данных
(a b c)
записанная в виде списка, требует трёх ячеек, хотя те же данные можно представить в виде
(a b . c)
требующем двух ячеек. Более компактное представление может несколько сократить и объём вычислений за счёт меньшего количества обращений в память.
Точечные пары применяются в теории, книгах и справочниках по Лиспу. Часто с их помощью обозначают список заранее неизвестной длины в виде:
(голова . хвост)
Точечные пары используются совместно с некоторыми типами данных и с ассоциативными списками, а также в системном программировании. Большинство программистов не используют точечные пары, поскольку по сравнению с требуемой в таком случае внимательностью получаемый выигрыш в объёме памяти и скорости вычислений обычно не заметен.
В результате вычислений в памяти могут возникать структуры, на которые потом нельзя сослаться. Это происходит в тех случаях, когда вычисленная структура не сохраняется с помощью setq или когда теряется ссылка на старое значение в результате побочного эффекта нового вызова setq или другой функции. Если, например, изображённому на рисунке списку list3
>(nil setq list3 '((this will garbage) rest part)) nil
присвоить новое значение
>(nil setq list3 (list3 rest)) nil
то first-часть как-бы отделяется, поскольку указатель из атома list3 начинает ссылаться так, как это изображено на рисунке при помощи серой стрелки.
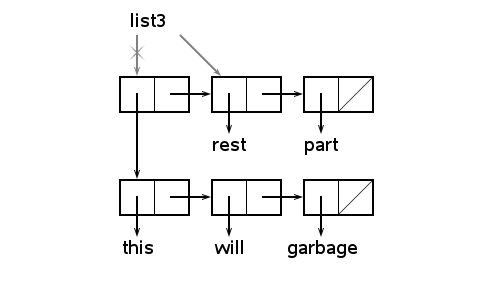
Теперь уже нельзя через символы и указатели добраться до четырёх списочных ячеек. Говорят, что эти ячейки стали мусором.
Мусор возникает и тогда, когда результат вычисления не связывается с какой-нибудь переменной. Например, значение вызова
>(nil cons 'a (nil list 'b)) (a b)
лишь печатается, после чего соответствующая ему структура останется в памяти мусором.
Для повторного использования ставшей мусором памяти предусмотрен специальный мусорщик, который автоматически запускается, когда в памяти остаётся мало свободного места. Мусорщик перебирает все ячейки и собирает являющиеся мусором ячейки в список свободной памяти для того, чтобы их можно было использовать заново.
Все рассмотренные до сих пор функции манипулировали выражениями, не вызывая каких-либо изменений в уже существующих выражениях. Например, функция cons, которая вроде бы изменяет свои аргументы, на самом деле строит новый список, функции first и rest в свою очередь лишь выбирают один из указателей. Структура существующих выражений не могла измениться как побочный эффект вызова функции. Значения переменных можно было изменить лишь целиком, вычислив и присвоив новые значения целиком. Самое большее, что при этом могло произойти со старым выражением, - это то, что оно могло пропасть.
В Лиспе всё-таки есть и специальные функции, при помощи которых на структуры уже существующих выражений можно непосредственно влиять так же, как, например, в Паскале. Это осуществляют функции, которые, как хирург, оперируют на внутренней структуре выражений.
Такие функции называют структура-разрушающими, поскольку с их помощью можно разорвать структуру и склеить её по-новому.
Основными функциями, изменяющими физическую структуру списков, являются setfirst и setrest, которые уничтожают прежние и записывают новые значения в поля first и rest списочной ячейки:
| (ячейка setfirst значение-поля) | ;поле first |
| (ячейка setrest значение-поля) | ;поле rest |
Объектом является указатель на списочную ячейку, аргументом - записываемое в неё новое значение поля first или rest. Обе функции возвращают в качестве результата указатель на изменённую списочную ячейку.
>(nil setq поезд '(паровоз1 a b c)) nil >(поезд setfirst 'паровоз2) (паровоз2 a b c) >поезд (паровоз2 a b c) >((поезд rest) setfirst 'тендер) (тендер b c) >поезд (паровоз2 тендер b c)
Функция setrest выполняется так же, как setfirst, с той разницей, что меняется значение поля rest:
>(поезд setrest '(k l m)) (паровоз2 k l m) >поезд (паровоз2 k l m)
Используя функцию setrest, можно, например, определить функцию круг, превращающую произвольный список в кольцо:
>(nil defmethod круг () (this делай-круг this))
(lambda nil (this делай-круг this))
>(nil defmethod делай-круг (x)
(nil cond
((nil atom this) this)
((nil atom (this rest)) (this setrest x))
(true ((this rest) делай-круг x))))
(lambda (x) (nil cond ((nil atom this) this) ((nil atom (this rest)) (this setrest x)) (true ((this rest) делай-круг x))))
>('(a b c) круг)
(c a b … c a b … )
Разумно использованные структура-разрушающие функции могут, как и нож хирурга, быть эффективными и полезными инструментами. Далее мы для примера рассмотрим, как можно с помощью структура-разрушающих псевдофункций повысить эффективность функции + для списков. Эта функция объединяет в один список списки, являющиеся его аргументами:
>(nil setq begin '(a b)) nil >(nil setq end '(c d)) nil >(nil setq result (begin + end)) nil
Может показаться, что приведённый выше вызов +, как бы изменяет указатели так, как это показано серыми стрелками.
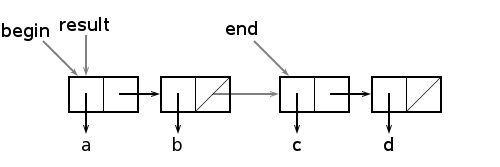
Однако это не верно, так как значение списка begin не может измениться, поскольку + не является структура-разрушающей функцией. Вычисляется и присваивается лишь новое значение переменной result. Мы получим структуры, изображённые на рисунке:
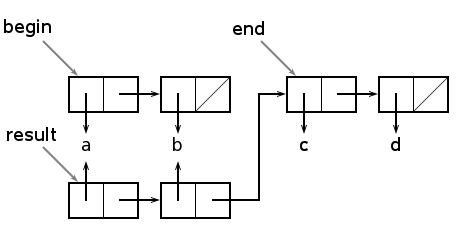
Из рисунка видно, что + создаёт копию списка, являющегося первым аргументом. Если этот список очень длинный, то долгими будут и вычисления. Создание списочных ячеек с помощью функции cons требует времени и в будущем добавляет работы мусорщику. Если, например, список begin содержит 1000 элементов, а end - один элемент, то во время вычисления будет создано 1000 новых ячеек, хотя вопрос состоит лишь в добавлении одного элемента к списку. Если бы расположение аргументов была другой, то создалась бы одна ячейка, и списки были бы объединены приблизительно в 1000 раз быстрее.
Если для нас не существенно, что значение переменной begin изменится, то мы можем вместо функции + использовать более быструю функцию +=. Функция += делает то же самое, что и +, с той лишь разницей, что она просто объединяет списки, изменяя указатель в поле rest последней ячейки списка, являющегося первым аргументом, на начало списка, являющегося вторым аргументом, как это показано на первом рисунке:
>('begin set '(a b))
(a b)
>('end set '(c d))
(c d)
>('result set (begin += end)) ; разрушающее объединение
(a b c d)
>begin ; побочный эффект
(a b c d)
>end
(c d)
Использовав функцию +=, мы избежали копирования списка begin, однако в качестве побочного эффекта изменилось значение переменной begin. Так же изменятся и все другие структуры, использовавшие ячейки первоначального значения переменной begin.
Псевдофункции, подобные setfirst, setrest и +=, изменяющие внутреннюю структуру списков, используются в том случае, если нужно сделать небольшие изменения в большой структуре данных. С помощью структура-разрушающих функций можно эффективно менять за один раз сразу несколько структур, если у этих структур есть совмещённые в памяти подструктуры.
Коварные побочные эффекты, вроде изменения значений внешних переменных, могут привести к сюрпризам в тех частях программы, которые не знают об изменениях. Это осложняет написание, документирование и сопровождение программ. В общем случае функции, изменяющие структуры, пытаются не использовать.